قابلیت حساب ساده در مسیرهای حافظهگیری نه در مدارهای منطقی حضور دارد.


اعتبار: بنج ادوردز / کیریلام از طریق گتی ایمیجز
هنگامی که مهندسان مدلهای زبانی هوش مصنوعی مانند GPT‑5 را از دادههای آموزشی میسازند، حداقل دو ویژگی پردازشی اصلی ظاهر میشوند: حافظهگیری (بازگو کردن دقیق متنی که پیشتر دیدهاند، مانند نقلقولهای مشهور یا بخشهایی از کتابها) و استدلال (حل مسائل جدید با بهکارگیری اصول کلی). پژوهش جدیدی از استارتاپ هوش مصنوعی Goodfire.ai شواهدی نسبتاً واضح ارائه میکند که این عملکردهای متفاوت واقعاً از طریق مسیرهای عصبی کاملاً جداگانه در معماری مدل کار میکنند.
پژوهشگران دریافتند که این جداسازی بهطور چشمگیری واضح است. در مقاله پیشنوشتهای که در اواخر اکتبر منتشر شد، آنها توضیح دادند که با حذف مسیرهای حافظهگیری، مدلها ۹۷٪ از توانایی خود برای بازگو کردن دقیق دادههای آموزشی را از دست دادند، اما تقریباً تمام قابلیت «استدلال منطقی» خود را حفظ کردند.
بهعنوان مثال، در لایهٔ ۲۲ از مدل زبانی OLMo‑7B مؤسسهٔ آلن برای هوش مصنوعی، ۵۰٪ پایینترین مؤلفههای وزن با ۲۳٪ فعالسازی بالاتر در دادههای حافظهگیری نشان دادند، در حالی که ۱۰٪ بالای این مؤلفهها با ۲۶٪ فعالسازی بالاتر در متنهای عمومی و غیرحافظهگیری مواجه بودند. این جداسازی مکانیکی به پژوهشگران امکان داد تا حافظهگیری را بهصورت جراحی حذف کنند و سایر قابلیتها را حفظ کنند.
بهنظر شاید شگفتانگیزترین نکته این بود که پژوهشگران دریافتند عملیات حسابی بهنظر میرسد همان مسیرهای عصبی حافظهگیری را بهجای استدلال منطقی بهکار میبرد. هنگامی که مدارهای حافظهگیری حذف شدند، عملکرد ریاضی به ۶۶٪ سقوط کرد در حالی که وظایف منطقی تقریباً بدون تغییر باقی ماندند. این کشف ممکن است توضیح دهد چرا مدلهای زبانی هوش مصنوعی بدون استفاده از ابزارهای خارجی بهطور بدنامی در ریاضیات مشکل دارند. آنها سعی میکنند محاسبههای ریاضی را از یک جدول محدود حافظهگیری بهخاطر بسپارند نه اینکه آن را محاسبه کنند، همانند دانشآموزی که جدول ضربها را حفظ کرده اما نحوهٔ ضرب را ندانسته است. این نتایج نشان میدهد که در مقیاسهای کنونی، مدلهای زبانی «۲+۲=۴» را بیشتر شبیه به یک حقیقت حافظهگیری میدانند تا یک عملیات منطقی.
قابل ذکر است که «استدلال» در پژوهشهای هوش مصنوعی شامل طیفی از تواناییهاست که لزوماً با آنچه که در انسانها «استدلال» مینامیم، همسو نیست. استدلال منطقی که در این پژوهش پس از حذف حافظهگیری حفظ شد شامل وظایفی مانند ارزیابی جملات درست/غلط و پیروی از قواعد اگر‑آنگاه است که در اصل بهکارگیری الگوهای یادگرفتهشده بر روی ورودیهای جدید میباشد. این در مقایسه با «استدلال ریاضی» عمیقی که برای اثباتها یا حل مسائل نوین لازم است، متفاوت است؛ مدلهای هوش مصنوعی کنونی حتی وقتی که تواناییهای تشخیص الگو را حفظ میکنند، در این زمینهها با مشکل مواجه میشوند.
در نگاه به آینده، اگر تکنیکهای حذف اطلاعات در آینده پیشرفت کنند، شرکتهای هوش مصنوعی میتوانند روزی محتویات دارای حقنشر، اطلاعات خصوصی یا متون مضر حافظهگیریشده را از یک شبکه عصبی حذف کنند، بدون اینکه توانایی مدل در انجام وظایف تحولگرایانه از بین برود. اما از آنجا که شبکههای عصبی اطلاعات را به‑صورت توزیعی ذخیره میکنند که هنوز بهطور کامل درک نشدهاند، پژوهشگران در حال حاضر میگویند روش آنها «نمیتواند حذف کامل اطلاعات حساس را تضمین کند». اینها گامهای اولیهٔ یک مسیر پژوهشی نوین برای هوش مصنوعی هستند.
سفر در منظرهٔ عصبی
برای درک نحوهٔ تمییز حافظهگیری از استدلال توسط پژوهشگران Goodfire در این شبکههای عصبی، آشنایی با مفهومی در هوش مصنوعی به نام «منظره زیان» مفید است. «منظره زیان» روشی برای تجسم درست یا نادرست بودن پیشبینیهای یک مدل هوش مصنوعی است که با تنظیم پارامترهای داخلی آن (که «وزنها» نامیده میشوند) تغییر میکند.
تصور کنید که یک دستگاه پیچیده با میلیونها تنظیمکننده (دایال) را تنظیم میکنید. «زیان» تعداد خطاهایی که دستگاه انجام میدهد را میسنجد. زیان بالا به معنای تعداد زیاد خطا، و زیان پایین به معنای خطاهای کم است. «منظره» همان تصویری است که اگر بتوانید نرخ خطا را برای هر ترکیب ممکن از تنظیمات دایالها ترسیم کنید، میبینید.
در طول آموزش، مدلهای هوش مصنوعی بهطور بنیادی «به سمت پایین» در این منظره (نزول گرادیان) حرکت میکنند و وزنهای خود را تنظیم مینمایند تا درههایی را پیدا کنند که در آنها کمترین تعداد خطا را داشته باشند. این فرآیند خروجیهای مدل هوش مصنوعی را تولید میکند، مانند پاسخ به سؤالات.
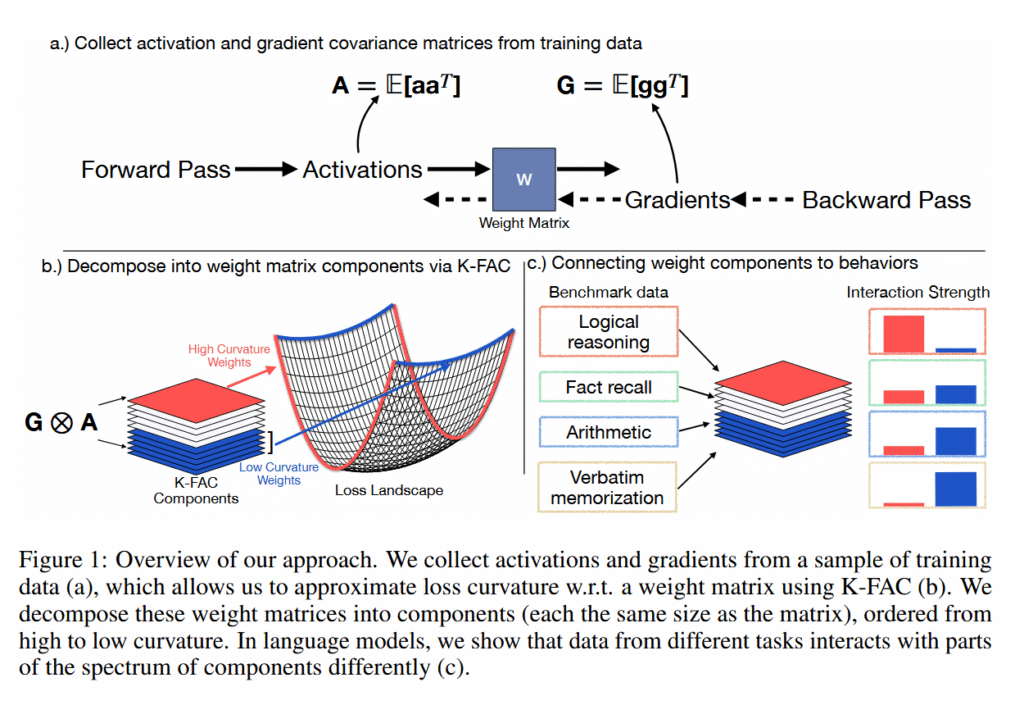
پژوهشگران «انحنای» مناظر زیان برخی مدلهای زبانی هوش مصنوعی را تجزیه و تحلیل کردند و میزان حساسیت عملکرد مدل نسبت به تغییرات جزئی در وزنهای مختلف شبکه عصبی را سنجیدند. قلهها و درههای تند نمایانگر انحنای بالا هستند (جایی که تغییرات کوچک اثرات بزرگ ایجاد میکند)، در حالی که دشتهای صاف نمایانگر انحنای پایین هستند (جایی که تغییرات تأثیر کمی دارند).
با بهکارگیری تکنیکی به نام K‑FAC (انحنای تقریبی فاکتور Kronecker)، آنها دریافتند که هر حقیقت حافظهگیری شده یک نقطهٔ تند در این منظره ایجاد میکند، اما از آنجا که هر مورد حافظهگیری شده در جهت متفاوتی برجسته میشود، هنگام میانگینگیری این نقاط یک نمایهٔ صاف میسازند. در مقابل، تواناییهای استدلال که بهوسیله ورودیهای متعدد بهکار گرفته میشوند، منحنیهای متوسطی سازگار در سراسر منظره حفظ میکنند؛ همانند تپههای ملایمی که شکل کلیشان تقریباً ثابت میماند، صرفنظر از جهت نزدیک شدن.
پژوهشگران مینویسند: «جهتهایی که مکانیزمهای مشترکی را که توسط بسیاری از ورودیها بهکار گرفته میشوند، بهصورت همافزا ترکیب میسازند و بهطور متوسط انحنای بالایی را حفظ میکنند»، که توصیفکننده مسیرهای استدلال است. برعکس، حافظهگیری از «جهتهای تند و خاصی که به مثالهای ویژه مربوط میشوند» بهره میبرد که هنگام میانگینگیری بر روی دادهها بهنظر میرسد صاف باشند.
وظایف مختلف طیفی از مکانیزمها را نشان میدهند
پژوهشگران تکنیک خود را بر روی چندین سیستم هوش مصنوعی آزمایش کردند تا اطمینان حاصل شود که نتایج در معماریهای مختلف ثابت میمانند. آنها عمدتاً از خانوادهٔ مدلهای زبانی باز OLMo‑2 مؤسسهٔ آلن استفاده کردند، بهویژه نسخههای ۷‑میلیارد و ۱‑میلیارد پارامتر، چون دادههای آموزشی آنها بهصورت عمومی در دسترس هستند. برای مدلهای بینایی، آنها Vision Transformers سفارشی با ۸۶ میلیون پارامتر (مدلهای ViT‑Base) را بر روی ImageNet با دادههای عمدتاً برچسبگذاریٔ اشتباه برای ایجاد حافظهگیری کنترلشده آموزش دادند. همچنین نتایج خود را در برابر روشهای موجود حذف حافظهگیری مثل BalancedSubnet برای تعیین معیارهای عملکردی اعتبارسنجی کردند.
تیم این کشف را با حذف انتخابی مؤلفههای وزن با انحنای پایین از این مدلهای آموزشدیده آزمایش کرد. محتوای حافظهگیری از تقریباً ۱۰۰٪ به ۳٫۴٪ بازیابی کاهش یافت. در عین حال، وظایف استدلال منطقی بین ۹۵ تا ۱۰۶٪ از عملکرد پایه را حفظ کردند.
این وظایف منطقی شامل ارزیابی عبارات بولی، معماهای استنتاج منطقی که حلکنندگان باید روابطی مانند «اگر A بلندتر از B باشد» را پیگیری کنند، ردیابی اشیاء از طریق چندین تعویض، و بنچمارکهایی همچون BoolQ برای استدلال بله/خیر، Winogrande برای استنتاج عقل سلیم، و OpenBookQA برای سؤالات علمی که نیاز به استدلال از حقایق ارائهشده دارند، میشد. برخی وظایف بین این دو قطب قرار گرفتند و طیفی از مکانیزمها را نشان دادند.
عملیات ریاضی و بازیابی حقایق بدون مراجعه به کتاب (closed‑book) مسیرهای مشترکی با حافظهگیری داشتند و پس از ویرایش عملکردشان به ۶۶ تا ۸۶٪ کاهش یافت. پژوهشگران دریافتند که حسابگیری بهویژه شکننده است. حتی زمانی که مدلها زنجیرههای استدلال یکسانی تولید میکردند، پس از حذف مؤلفههای وزن با انحنای پایین، در گام محاسبه شکست میخوردند.
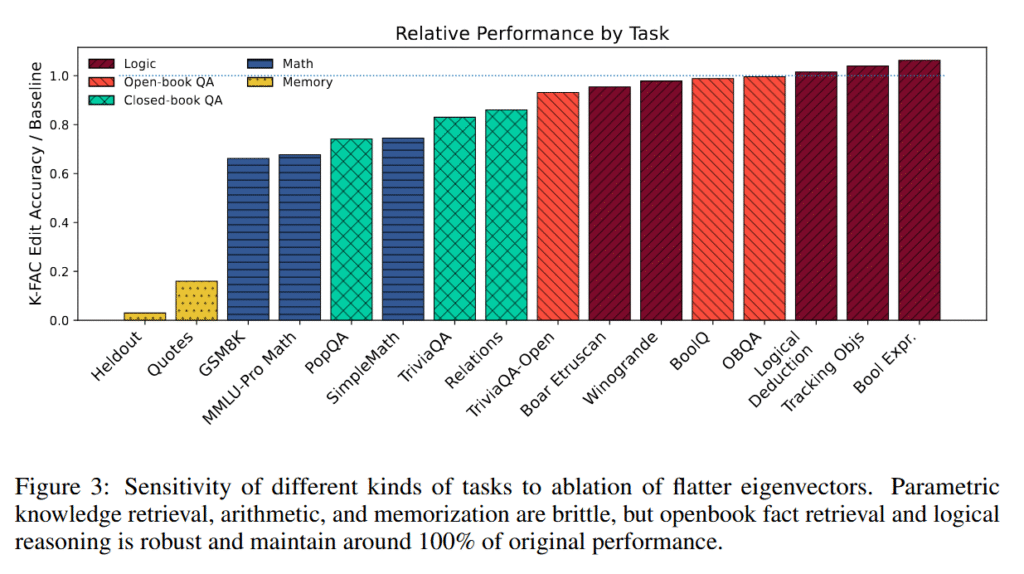
تیم توضیح میدهد: «مشکلات حسابی خود در مقیاس ۷B بهصورت حافظهگیری میشوند، یا به این دلیل که برای محاسبات دقیق به جهتهای بسیار خاصی نیاز دارند». پاسخگویی به سؤالات کتاب باز (Open‑Book) که بهجای دانش داخلی بهمتن فراهمشده وابسته است، بیشترین مقاومت را در برابر فرآیند ویرایش نشان داد و تقریباً تمام عملکرد را حفظ کرد.
جالب است که جداسازی مکانیزمها بسته به نوع اطلاعات متفاوت بود. حقایق رایج مانند پایتختهای کشورها پس از ویرایش تقریبا بدون تغییر باقی ماندند، در حالی که حقایق نادر مانند مدیران عامل شرکتها ۷۸٪ کاهش یافتند. این نشان میدهد که مدلها منابع عصبی متمایزی را بر پایهٔ فراوانی ظهور اطلاعات در دادههای آموزشی تخصیص میدهند.
تقنیک K‑FAC بدون نیاز به نمونههای آموزشی محتوای حافظهگیری شده، عملکرد بهتری نسبت به روشهای موجود حذف حافظهگیری داشت. در نقلقولهای تاریخی که پیشاز این مشاهده نشده بودند، K‑FAC ۱۶.۱٪ حافظهگیری را در مقایسه با ۶۰٪ روش پیشینترین، BalancedSubnet، بهدست آورد.
Vision Transformers نیز الگوهای مشابهی نشان دادند. هنگامی که با تصاویری که عمداً برچسبگذاری نادرست شدهاند آموزش داده شدند، مدلها مسیرهای متمایزی برای حافظهگیری برچسبهای اشتباه و یادگیری الگوهای صحیح ایجاد کردند. حذف مسیرهای حافظهگیری دقت ۶۶٫۵٪ را در تصاویری که قبلاً برچسب اشتباه داشتند، بازگرداند.
محدودیتهای حذف حافظه
با این حال، پژوهشگران اذعان کردند که روش آنها کامل نیست. حافظههای حذفشده ممکن است در صورتی که مدل بهسختیهای بیشتری بپردازد، بازگردند؛ همانطور که پژوهشهای دیگر نشان دادهاند روشهای فعلی فراموشکردن تنها اطلاعات را سرکوب میکنند و بهطور کامل از وزنهای شبکه عصبی پاک نمیسازند. این به این معناست که محتوای «فراموششده» میتواند تنها با چند گام آموزش که به این مناطق سرکوبشده هدفگذاری میکند، مجدداً فعال شود.
پژوهشگران همچنین نمیتوانند بهطور کامل توضیح دهند چرا برخی توانمندیها، مانند ریاضیات، هنگام حذف حافظهگیری بهآسانی شکست میخورند. واضح نیست که آیا مدل تمام محاسبات ریاضی خود را حافظهگیری کرده است یا اینکه ریاضیات بهتصادف از مدارهای عصبی مشابه با حافظهگیری استفاده میکند. علاوه بر این، برخی قابلیتهای پیشرفته ممکن است بهنظر روش تشخیص آنها، حافظهگیری به نظر برسند، حتی اگر در واقع الگوهای استدلال پیچیدهای باشند. نهایتاً، ابزارهای ریاضیاتی که برای سنجش «منظره» مدل به کار میبرند در نقاط انتهایی ممکن است بیاعتمادی شوند؛ اگرچه این موضوع بر خود فرآیند ویرایش تأثیری ندارد.